We present a deep-learning-based interactive system for singing-voice separation from input polyphonic music signals. This system allows a user to interactively fine-tune the deep neural model at run time to adapt it to the target song. This human-in-the-loop model adaptation can improve separation quality.
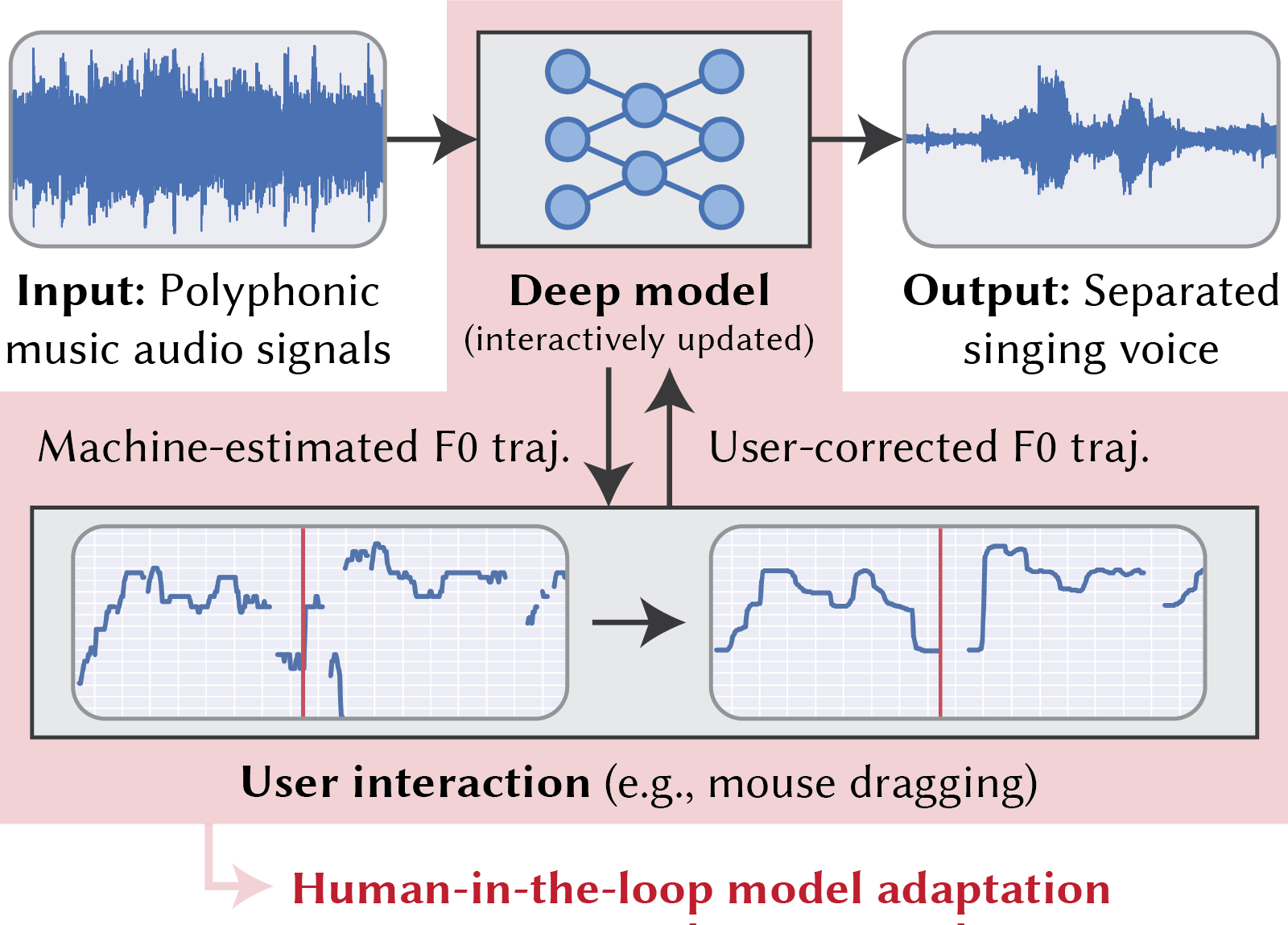
Interactive deep singing-voice separation. The user can interact with the deep model to fine-tune the quality of the separated singing voice. The user feedback is provided as F0 trajectories, based on which the model is adapted.
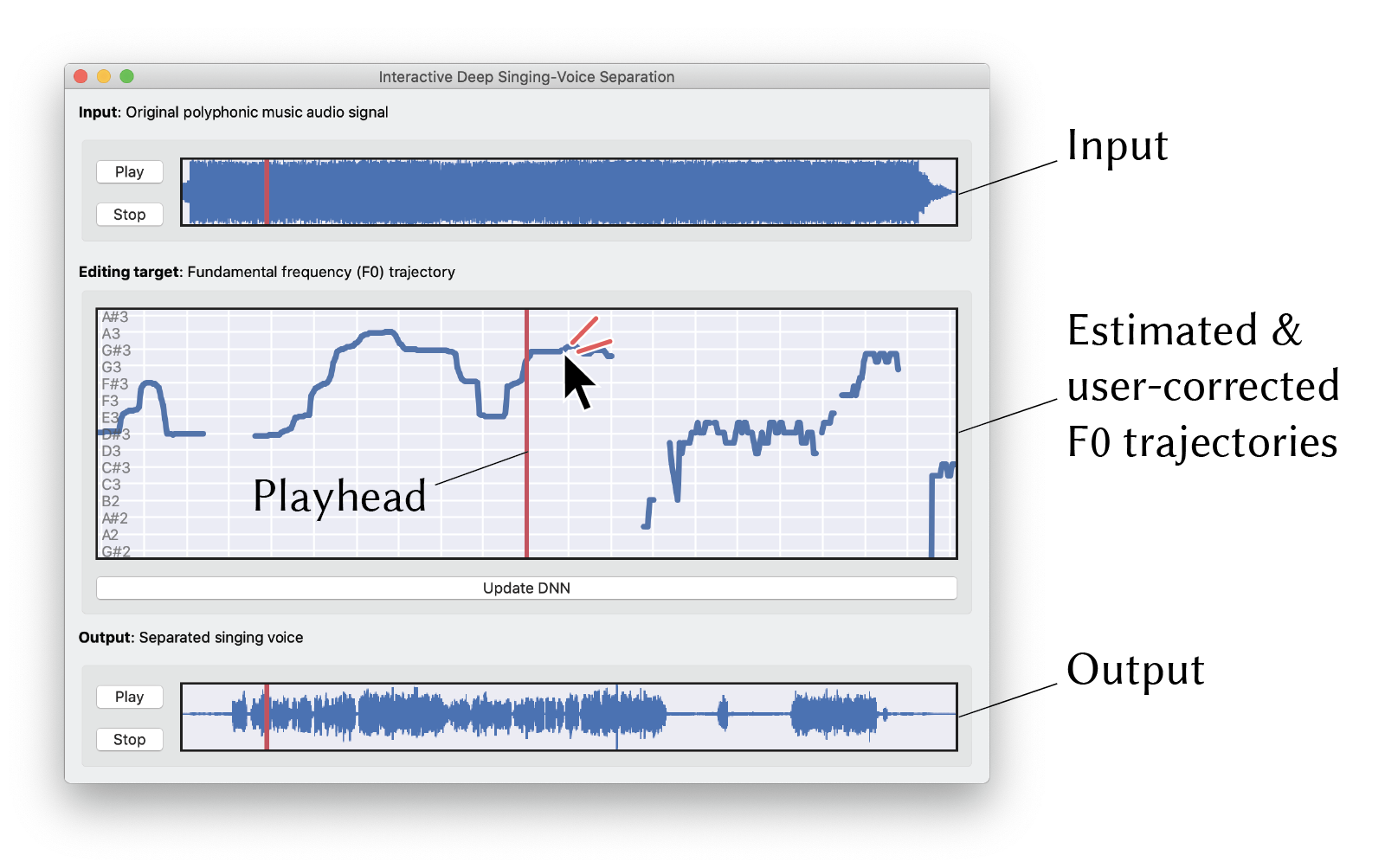
Screen capture of our prototype system. (Top) Input polyphonic music audio signals. (Middle) Widget for correcting the estimated F0 trajectory. (Bottom) Current output of the separated-singing voice.
This paper presents a deep-learning-based interactive system separating the singing voice from input polyphonic music signals. Although deep neural networks have been successful for singing voice separation, no approach using them allows any user interaction for improving the separation quality. We present a framework that allows a user to interactively fine-tune the deep neural model at run time to adapt it to the target song. This is enabled by designing unified networks consisting of two U-Net architectures based on frequency spectrogram representations: one for estimating the spectrogram mask that can be used to extract the singing-voice spectrogram from the input polyphonic spectrogram; the other for estimating the fundamental frequency (F0) of the singing voice. Although it is not easy for the user to edit the mask, he or she can iteratively correct errors in part of the visualized F0 trajectory through simple interaction. Our unified networks leverage the user-corrected F0 to improve the rest of the F0 trajectory through the model adaptation, which results in better separation quality. We validated this approach in a simulation experiment showing that the F0 correction can improve the quality of singing-voice separation. We also conducted a pilot user study with an expert musician, who used our system to produce a high-quality singing-voice separation result.





Tomoyasu Nakano, Yuki Koyama, Masahiro Hamasaki, and Masataka Goto. 2020. Interactive Deep Singing-Voice Separation Based on Human-in-the-Loop Adaptation. In Proceedings of the 25th International Conference on Intelligent User Interfaces (IUI '20), pp.78--82.
DOI: 10.1145/3377325.3377539